napari-n2v
A self-supervised denoising algorithm.
Documentation
napari-n2v is based on the original algorithm from the Jug lab Noise2Void, and uses
CSBDeep. N2V is a self-supervised algorithm
that allows denoising images by removing pixel-independent noise. It also comprises an extension to deal with
structured noise, and checkboard artefacts with N2V2.
napari-n2v contains two different napari plugins: N2V train and N2V predict.
N2V train
Anatomy
- GPU availability
- Data loading
- Training parameters
- Expert training parameters
- Training
- Training progress
- Prediction
- Model saving
1 - GPU availability
This small widget checks whether a GPU device is available to TensorFlow. If the GPU is available, then you will see the following:

If the GPU is not available, the widget will show a yellow CPU.
GPU availability does not ensure that the code will run on the GPU, but it is a necessary condition.
2 - Data loading
The data loading panel has two tabs: From layers and From disk :
- From layers:
Choose among the available napari layers data for the
TrainandVal. Note that ifValis empty or equal toTrain, a portion of the training data will be extracted as validation data. - From disk:
Use the
choosebutton to point to folders containing images. The images can be of different dimensions but should have the same axes (e.g. TXY). Note that ifValis empty or equal toTrain, a portion of the training data will be extracted as validation data. When selecting a folder for theTrainset, the first image will be loaded as sample into napari to estimate the axes (see Axes in the next section).
3 - Training parameters

The training parameters are the basic settings you can use to tune your N2V training:
Axes: This widget allows specifying your data axes order. Only a few axes are allowed: S(ample) (equivalent to a roi), T(ime), Z, X, Y and C(hannel), in any order. This knowledge is important for the algorithm as not all axes are treated the same way. S and T axes are merged, as time points are considered independent regions of interest. Z, X and Y are moved to their respective place. Finally, if a C axis exists, independent networks are trained for each channel. The default text is the most likely axes order, and depends on whether the data has a Z dimension (seeEnable 3D). The axes widget text is highlighted in orange if there are not enough (or too many) axes with respect to the images (in the layers or a sample loaded from the disk) or ifEnable 3Dis selected but noZappears in theAxes. The text turns red when an axis is duplicated or invalid. Training can only start when the axes widget has a valid entry.Enable 3D: Select for data with a Z dimension. Enabling Z changes the constraints ofAxesand allows setting aPatch Z.N epochs: The number of epochs is meant to be the number of times the network will see the whole training data set during training. The more epochs, the longer the training.N steps: The steps are the number of image batches used for training during an epoch. The number of steps should be set so as to approximately verify the following equality: $S = P / B$ where $S$ is the number of steps, $P$ the number of patches and $B$ the batch size (seeBatch size). The number of patches can be difficult to estimate, as it depends onPatch XY, the size of your images and augmentation. The output of the plugin prints the number of patches to the terminal.Batch size: Size of the image batch used at each step. Note that because the batches are loading directly onto the GPU, large batches can cause out of memory (OOM) errors. If GPU memory is a problem, reduce the batch size.Patch XY: Dimensions in X and Y of the patches. Patches are extracted from the images. Patch size should be large enough to encompass useful details about the local structures of the image. Large patch size will cause the batches to be too large for the GPU memory, and should therefore be reduced should the memory be limiting. Note that path size should a multiple of 8 and no smaller than 16. If the patch size is too small, N2V can throw an error because less than 1 pixel is masked per patch, in such case increase the percentage of masked pixels (see Expert settings).Patch Z: Similar toPatch XY, albeit for the Z axis.
4 - Expert training parameters
The expert training parameters can be set by clicking on the gear button, modifying the relevant settings and closing the window.
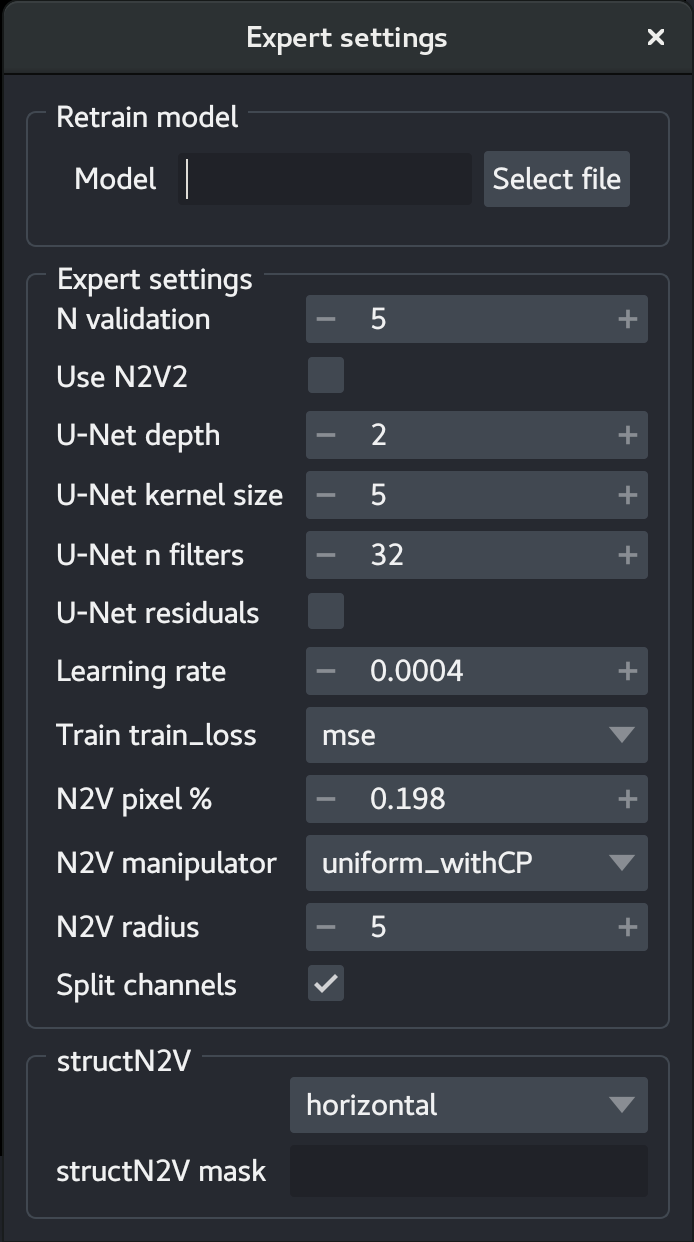
Model: Select a.h5or.biomage.io.zipfile to retrain a model. The models should be compatible. The plugin will automatically search for aconfig.jsonfile in the same folder and throw an error if not found.N validation: Number of patches extracted from the training set to use as validation. This setting is only used when the training and validation layers or folders are the same.Use N2V2: Use a variant of N2V2 that mitigates check-board artefacts. This variant uses a slightly different architecture and amedianpixel manipulator. This is currently only possible in 2D.U-Net depth: Depth of the underlying U-Net architecture. Larger architectures are capable of generalizing better but are more complex to train.U-Net kernel size: Size of the convolution filters in all dimensions.U-Net n filters: Number of filters in the first convolutional layers. This value is doubled after each down-sampling operation.U-Net residuals: Predict deep residuals internally.Learning rate: The learning rate influences the speed of convergence.Train loss: Loss used during training: mean average error (mae) oN2V pixel %: Percentage of patch pixels to be masked.N2V manipulator: Masking methods.N2V radius: Parameter of theN2V manipulator.Split channels: Train a single network per channel when checked.structN2V: Mask used to allow removing structured noise (see Broaddus et al). The mask is one-dimensional and can be oriented vertically or horizontally to remove correlations between pixel along the same dimension.structN2V maskis a comma-separated sequence of0and1. The sequence should have an odd length. A central1is added to even-length sequences. An example ofstrucN2V maskis0,1,1,1,1,1,0.
5 - Training
Depending on the stage of the training, the Training panel has different buttons:
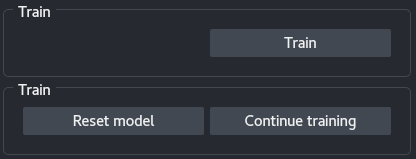
Train: Start training a network on the data given the current parameters.Stop: Stop the training. This enables predicting on the training and validation images (see Precition), as well as saving the trained model (see Model saving).Reset model: Reset the model, the next training session will be from scratch. After resetting the model, information on the previously trained network is lost and prediction or saving the model is no longer possible.Continue training: Continue training using the current parameters but the trained network weights. Note that the training and validation patches will change ifTrainandValare the same.
During training, the log and the weights are saved to a hidden folder in your /home/, under .napari/N2V/models.
6 - Training progress
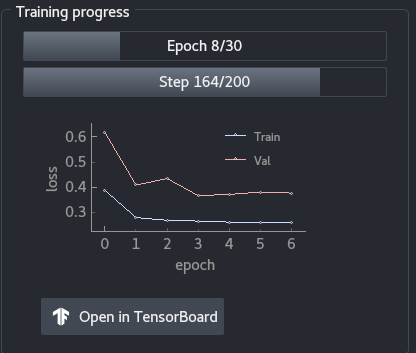
The training progress panel shows the following:
- Progress in terms of epochs
- Progress in terms of steps for the current epoch
- Training and validation loss throughout the epochs. You can use the mouse wheel to zoom in or out of the graph, and you can click on the
Abutton to resize automatically the graph. Open in TensorBoardopens TensorBoard in a new tab in your browser.
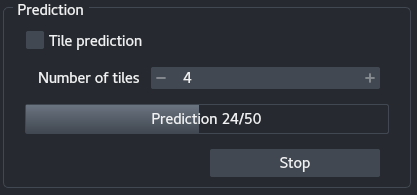
7 - Prediction
Prediction is available after training. If you wish to predict on a different set of images or with a model saved to the disk, use the N2V - predict plugin.
The prediction is ran on the Train and Val data that were saved in memory before training. If the images where loaded directly from the disk and they have different dimensions (X, Y, Z), then the results are saved to the disk in a /result/ folder. Otherwise, the predicted images are added to napari.
After training, the panel contains the following elements:
Tile prediction: Use tiling to predict the images. Tiling allows breaking large images in smaller chunks in order to fit in the GPU memory.Number of tiles: Number of tiles to user per image.- A progress bar showing the progress in terms of predicted images (
Train+Val). Predict: Start the prediction.Stop: Stop the prediction.
Note: Prediction can take a while to start so be patient and check console outputs to make sure it is running correctly.
8 - Model saving

After training, the model can be saved to the location of your choice. Aside from saving the model weights, the plugin also saves a config.json file containing all the parameters of the training.. The model weights can be saved in two formats:
[Bioimage.io](http://Bioimage.io): The Bioimage.io format.TensorFow: The model is saved as a.h5file.
N2V predict
Anatomy
Multiple aspects of the N2V - predict plugin are similar to the N2V - train plugin, refer to the latter one for missing information.
1 - Data loading
Data can be loaded directly from napari layers or from the disk.
- From napari layers: The predicted images will be added to napari in a new layer but will not be saved to the disk.
- From disk:
If the images can be stacked (same X, Y and, if applicable, Z dimensions), then the predictions will be added to napari as a new layer but will not be saved to the disk.
If they can’t be stacked, then the images are all loaded as a list and the predictions are saved to the disk in the same folder, under
/results/. In addition, alazy loadingcheckbox allows predicting the images one at a time. Note that iflazy loadingis selected, the images are saved to the disk directly even if their dimensions match.
Note that if you select a training folder, the plugin will try to load the first image it finds in order to assert the axes.
2 - Parameters
The parameters Axes and Enable 3D are similar to the corresponding ones in N2V - Train. In addition, model weights should be loaded from the disk and should correspond to a config.json file in the same folder. The plugin throws an error if no configuration is found.
3 - Tiling
Refer to the description of tiling in N2V - Train.
4 - Predict
Apply the model to the images. See the previous sections for details about the prediction modalities.